Doing UTF-8 in Windows #
Introduction #
This article shows how to handle UTF-8 encoding on a platform that still encourages the UTF-16 encoding. I am also providing a small library for this purpose. The code works, it is clean, easy to understand and small.
This is an implementation of the solution advocated in the UTF-8 Everywhere manifesto. I would strongly encourage you to go read the whole document to get indoctrinated ☺.
Background #
Let me rehash some of the points made in the manifesto mentioned above:
- UTF-16 (variously called Unicode, widechar or UCS-2) was introduced back in early ‘90-es and, at the time, it was believed that its 65000 codes will be enough for all characters,
- Except in particular cases, UTF-16 is not more efficient or easier to use than UTF-8. In fact in many cases the opposite is true.
- In UTF-16 characters have also variable width encoding (two or four bytes) and counting characters is as difficult as in UTF-8.
If you want to work with UTF-8 encoding in Windows (and you should), and you don’t want go insane or your program to crash unexpectedly you must follow the following rules:
- Define
_UNICODEwhen compiling your program (or select “Use Unicode Character Set” in Visual Studio). - Use
wchar_torstd::wstringonly in arguments to API function calls. Usecharorstd::stringeverywhere else. - Use
widen()andnarrow()functions to go between UTF-8 and UTF-16.
The functions provided in this library will make your life much easier.
Calling Library Functions #
All functions live in the utf8 namespace and I would advise you not to place a using directive for this namespace. This is because many/most functions have the same name as the traditional C functions. For instance, if you had a function call:
mkdir (folder_name);
and you want to start using UTF-8 characters, you just have to change it to:
utf8::mkdir (folder_name);
Prefixing the function with the namespace makes it obvious what function you are using.
Basic Conversion Functions #
Following the same manifesto, the basic conversion functions are narrow(), to go from UTF-16 to UTF-8 and widen() to go in the opposite direction. Their signatures are:
std::string narrow (const wchar_t* s);
std::string narrow (const std::wstring&; s);
std::wstring widen (const char* s);
std::wstring widen (const std::string&; s);
In addition there are two more functions for conversion from and to UTF-32:
std::string narrow (const std::u32string&; s);
std::u32string runes (const std::string&; s);
Internally, the conversion is done using the WideCharToMultiByte and MultiByteToWideChar functions.
There are also functions for counting the number of characters in a UTF-8 string (length()), to check if a string is valid (valid()), and to increment/decrement a pointer/iterator in character string (next() and prev()).
Wrappers #
Pretty much all the other functions are wrappers around traditional C/C++ functions or structures:
- directory manipulation functions:
mkdir,rmdir,chdir,getcwd - file operations:
fopen,chmod,access,rename,remove - streams:
ifstream,ofstream,fstream - path manipulation functions:
splitpathandmakepath - environment access functions:
putenvandgetenv - program execution:
system - character classification functions
is...(isalnum,isdigit,isalpha, etc.)
The parameters for all these functions mimic the standard parameters. For some of them however, like access, rename, etc., the return type is bool with true indicating success and false indicating failure. This is contrary to standard C functions that return 0 for success. Caveat emptor!
There are also wrapper functions for popular Win32 API functions:
- Registry API (
RegCreateKey,RegOpenKey,RegSetValue,RegGetValue, etc.) - Other useful functions (
MessageBox,LoadString,ShellExecute,CopyFile, etc.)
Return Values #
For API functions that return a character string, you would need to setup a wchar_t buffer to receive the value, convert it to UTF-8 using a narrowing function and eventually release the buffer. Below is an example of how this would look like. The code retrieves the name of temporary file:
wstring wpath (_MAX_PATH, L'\0');
wstring wfname (_MAX_PATH, L'\0');
GetTempPath (wpath.size (), const_cast<wchar_t*>(wpath.data ()));
GetTempFileName (wpath.c_str(), L"ABC", 1, const_cast<wchar_t*>(wfname.data ()));
string result = utf8::narrow(wfname);
This seemed a bit too cumbersome and error prone so I made a small object destined to hold returned values. It has operators to convert it to a wchar_t buffer and then to a UTF-8 string. For lack of a better name, I called it buffer. Using this object, the same code fragment becomes:
utf8::buffer path (_MAX_PATH);
utf8::buffer fname (_MAX_PATH);
GetTempPath (path.size (), path);
GetTempFileName (path, L"ABC", 1, fname);
string result = fname;
Internally, a buffer object contains UTF-16 characters but the string conversion operator invokes the utf8::narrow function to convert the string to UTF-8.
Program Arguments #
There are two functions for accessing and converting UTF-16 encoded program arguments: the get_argv function returns an argv like array of pointers to commend line arguments:
int argc;
char **argv = utf8::get_argv (&argc);
The second one provides directly a vector of stings:
std::vector<std::string> argv = utf8::argv ();
When using the first function, one has to call utf8::free_argv function to release the memory allocated for argv array.
Unexpected Twists - C++20 and UTF-8 #
The C++20 standard has added an additional type char8_t, designed to keep UTF-8 encoded characters, and a string type std::u8string. By making it a separate type from char and unsigned char, the committee has also created a number of incompatibilities. For instance the following fragment will produce an error:
std::string s {"English text"}; //this is ok
s = {u8"日本語テキスト"}; //"Japaneese text" - error
You would have to change it to something like:
std::u8string s {u8"English text"};
s = {u8"日本語テキスト"};
In my opinion, by introducing the char8_t type, the committee went against the very principles of UTF-8 encoding. The purpose of the encoding was to extend usage of the char type to additional Unicode code points. It has been so successful that it is now the de-facto standard used all across the Internet. Even Windows, that has been a bastion of UTF-16 encoding, is now slowly moving toward UTF-8.
In this context, the use of char data type for anything other than holding encodings of strings, seems out of place. In particular, arithmetic computations with char or unsigned char entities are just a small fraction of the use cases. The standard should try to simplify usage in the most common cases leaving the infrequent ones to bear the burden of complexity.
Following this principle, you would want to write:
std::string s {"English text"};
s += " and ";
s += "日本語テキスト";
with the implied assumption that all char strings are UTF-8 encoded character strings.
Recently (June, 2022) the committee seems to have changed position and introduced a compatibility and portability fix - DR2513R3 allowing initialization of arrays of char or unsigned char with UTF-8 string literals. Until the defect report makes its way into the next standard edition, the solution for Visual C++ users who compile under C++20 standard rules is to use the Zc:char8_t- compiler option.
Belt-and-suspenders - Windows ANSI code page #
Starting with Windows version 1903 (March 2019 update), Microsoft allows you to set UTF-8 as the system ANSI code page (ACP). This allows you to use the -A versions of API functions instead of the -W ones. The setting is buried deep, under three levels of dialog boxes.
Go to “Settings > Time and Language > Language and Region” and select “Administrative language settings”: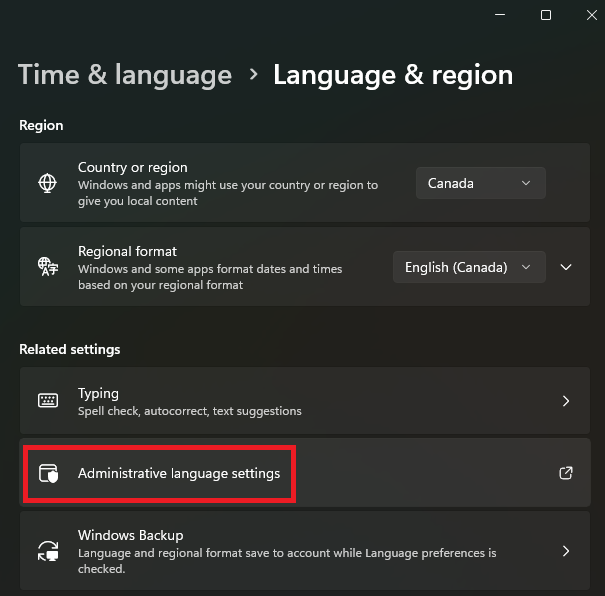
In the next dialog box select “Change system locale”: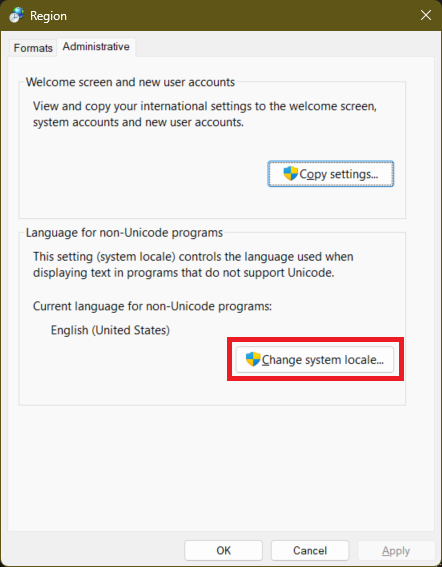
Finally, check the “Beta: Use Unicode UTF-8 for worldwide language support” checkbox: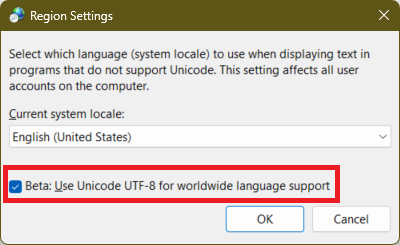
More information can be found here: Use UTF-8 code pages in Windows apps
‘What’s the advantage?’ you may ask. ‘You said before that I should define _UNICODE to make sure that only -W API functions get called.’ Well, this is true for Windows API functions but for C functions there are no -A and -W variants. If you have a call to fopen like in the program below:
int main()
{
const char* greeting = u8"Γειά σου Κόσμε!\n"; //Hello world
const char* filename = u8"όνομααρχείου.txt";
FILE* f = fopen(filename, "w");
fprintf(f, greeting);
fclose(f);
return 0;
}
you might not notice that you called fopen function instead of utf8::fopen. Running this program on a Windows machine with the default ANSI code page (frequently 1252) will produce this result:
However, if Windows is set to use UTF-8 ACP, even the call to standard fopen will produce the correct filename:
Also output to std::cout will be properly shown as UTF-8 encoded text.
A word to the wise: you should check if Windows is set to use UTF-8 code page using GetACP function:
if (GetACP() != 65001)
std::cout << "Warning! not using UTF-8 ANSI code page\n";
Otherwise, if your development machine is set to use the UTF-8 ANSI code page, you run the risk of having your application certified “Works On My Machine”.
History #
- 22-Nov-2019 - Initial version.
- 30-May-2023 - Added discussion about C++20
char8_t - 08-Oct-2023 - Added instructions for changing ACP